大语言模型选择和参数调整
模型选择
ECNU智能体开发平台提供了丰富的大语言模型,就像不同型号的汽车 —— 有 “小型车”“中型车”“大型车” 之分。有的模型擅长快速生成文字内容,好比 “跑车” 能在写作、创意场景中疾驰;有的模型具备强大的逻辑推理能力,如同 “载货卡车”,适合处理复杂的数据计算、学术研究等重任务。
我们会根据用户的实际使用反馈、平台资源情况(如算力、数据),灵活优化模型配置,就像给汽车升级引擎、变速箱等部件。对用户而言,只需根据需求首次选好 “车型”(模型类型),后续的性能升级无需额外操作,平台会自动完成迭代,让模型始终保持最佳状态。
如果你想做一个能写文章、写诗的智能体,就可以选择在语言生成方面表现突出的模型;要是做一个数学解题助手或者逻辑推理助手,那就选推理能力强的模型。可以多尝试不同的模型,对比它们在相同任务下的表现,找到最适合自己需求的那一个。
参数调整
模型的参数会直接影响它的输出结果。
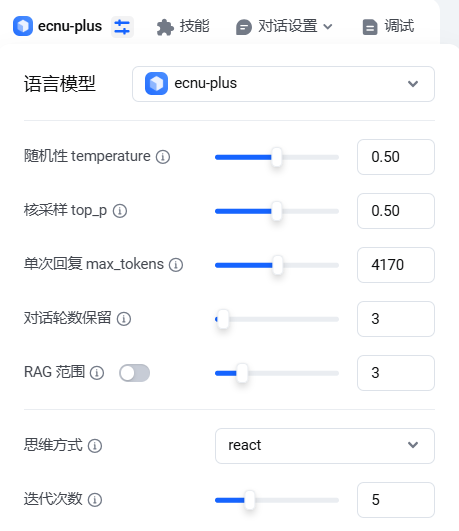
随机性temperature:这个参数的取值范围是0 - 1,它控制着输出的随机性。当值越大时,输出会更随机、更有创造性,比如在写故事、创作诗歌的时候,把这个值调大一点,可能会得到更富有想象力的内容;当值越小时,输出就越稳定、越确定,在查询一些事实性信息,像历史事件、科学知识时,把值调小能保证回答更准确。
核采样top_p:它和随机性有点类似,也是控制输出的多样性。值越大,输出包含的单词选项就越多,内容会更加丰富多样;值越小,输出就更集中在高概率单词上,回答会更确定,但可能会缺少一些多样性。一般来说,随机性和核采样这两个参数只需要设置其中一个就可以了。
max_tokens单次回复:这个参数限定了模型每次输出内容的最大token数,简单理解就是输出内容的长度。如果设置得太小,回答可能会不完整,有些关键信息就没办法传达出来;设置得太大,可能会浪费资源,还可能受到一些限制。通常情况下,设置为4096左右比较合适,但具体也要根据实际任务和需求来调整。
对话轮数保留:它决定了智能体能够记住多少轮对话内容。数值越大,多轮对话之间的相关性就越高,智能体就好像记忆力更好,能根据前面的对话更好地理解用户的需求。比如做一个连续对话的客服智能体,就需要把这个值设置得大一点,这样它就能更好地连贯地和用户交流;但如果对话轮数保留得太多,也会消耗更多的资源。
RAG 范围:该参数用于控制智能体在检索知识库时携带的对话历史轮数(仅包含问题)。数值越大,智能体在检索时会结合更多轮次的上下文信息,使知识库匹配更精准,但会增加 Token 消耗和检索耗时。例如,在处理高校教育场景的复杂多轮问答(如毕业论文指导)时,建议将 RAG 范围设为 3-5 轮,确保智能体基于历史问题准确调取相关学术规范、文献案例等知识片段;若为单轮课程知识点查询,可设为 1 轮以减少资源占用。
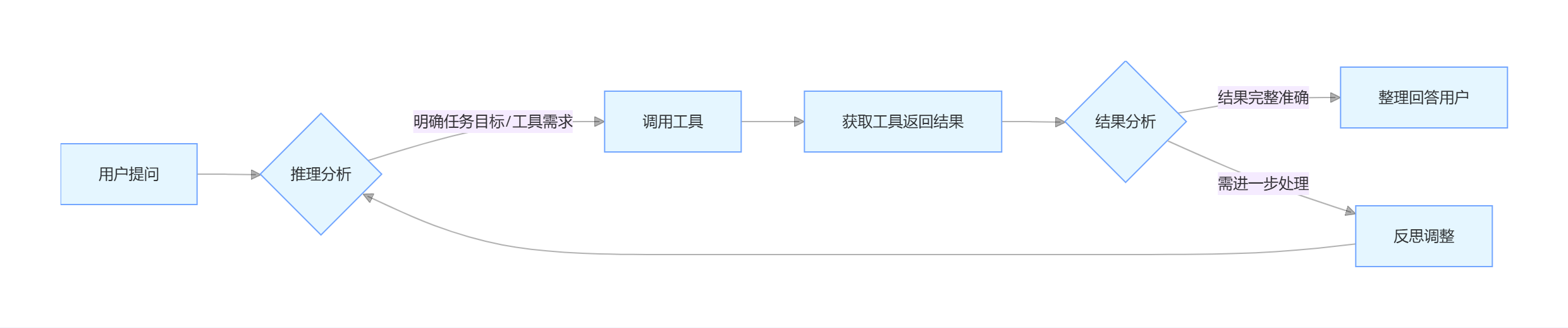
思维方式:平台支持多种智能体核心算法,典型如react(推理与行动)、Plan and Execute(计划 - 执行)和function_call(工具调用)。
- react(推理与行动):适合需要动态调用工具 / 知识库的场景,通过 “推理→调用工具→观察结果→反思” 循环处理任务。高校教育场景示例:开发 “学术文献调研智能体” 时,智能体先推理用户研究方向(如 “人工智能在教育中的应用”),调用学术数据库插件检索最新论文,再根据检索结果反思是否需要补充关键词或调整检索策略,直至获取足够文献资料。
- plan and execute(计划 - 执行):适用于需预先规划步骤的复杂任务(如课程设计报告撰写)。智能体先输出完整任务计划(如 “确定主题→文献综述→方案设计→实验验证→结论总结”),再按步骤逐个执行,适合需要全局规划的场景,但响应时间较长。
- function_call(工具调用):支持智能体直接调用外部工具接口(如论文查重 API、数据可视化工具等)。例如,在 “论文质量优化智能体” 中,智能体可调用查重工具 API 获取重复率数据,再基于结果生成降重建议,实现 “检测 - 分析 - 优化” 自动化流程。
迭代次数:指智能体在处理任务时最多允许的思考轮数,取值范围通常为 1-10。数值越大,智能体可进行更多次工具调用或反思优化,但会延长响应时间。例如,在 “高校作业批改智能体” 中,设置迭代次数为 3,智能体可自动完成 “初步评分→错误定位→改进建议生成” 的多轮迭代,确保批改意见的准确性和针对性;若为简单选择题自动判卷,设置为 1 次即可快速返回结果。