常见术语概念
基础概念组(推荐阅读)
🔔 以下基础概念建议先了解下~包括这些小伙伴:知识库、提示词、插件、工作流、数据库
💾知识库:智能体的「记忆仓库」
知识库是存储各类信息的「资料库」,类似图书馆的书架📚,包含校园通知、学术文献、食堂菜单等内容。
当用户提问时,智能体通过「检索增强生成(RAG)」技术(此处只要知道有这么一种技术)从知识库中调取相关信息 :
- 先将问题转化为向量(向量是特定术语,可以理解为转化成一种指定的格式,知识库中所有存储的信息提前都转化为了向量,这样可以进行对比)
- 再与知识库中的文本片段进行语义匹配(如查找 “图书馆借书流程” 时,系统会定位到对应文档片段)
- 最后结合大语言模型生成回答(大模型是智能体的“大脑”,会结合知识库内容,加以理解组合后输出,不同类型的大模型加工后,输出的表达效果略有差别)
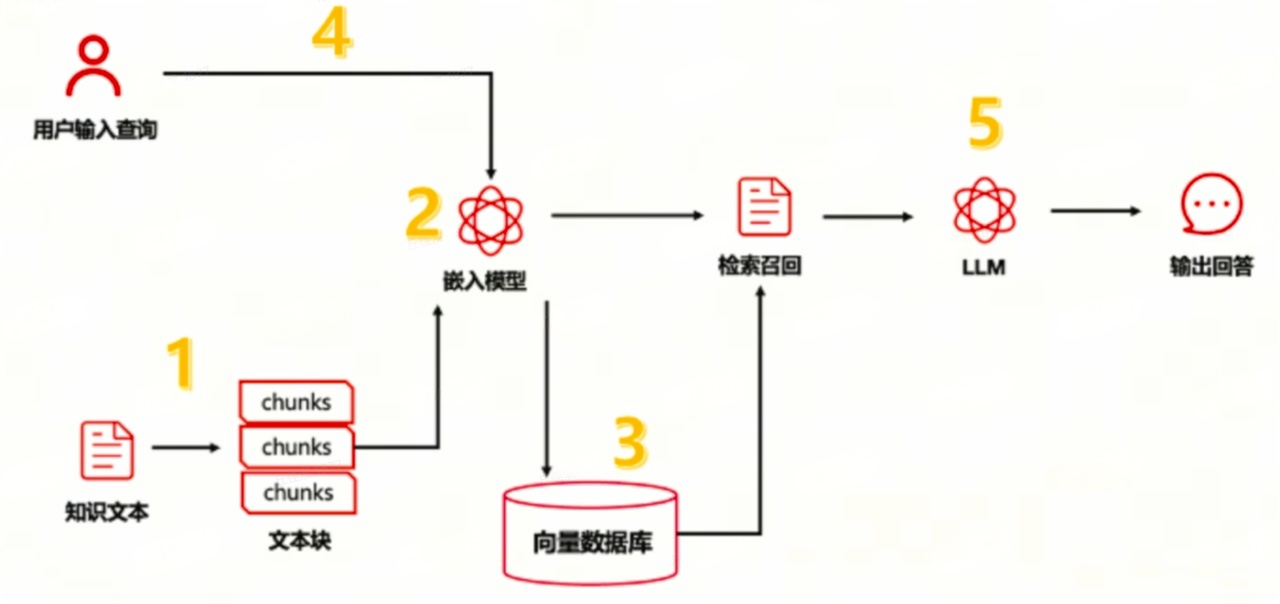
核心流程图参考如下:
- 文档预处理:删除无效数据、统一格式(如去除空白字符)等;
- 分片切割:按字数(如 10000 字)或标点将长文本拆分为独立片段;
- 向量化存储:嵌入模型将片段转为计算机可理解的向量(如 “国王” 的词向量为 [0.2, -0.1, 0.5...]),存入向量数据库;
- 检索生成:用户提问→向量匹配→大模型整合信息→输出答案。
📜提示词:与智能体沟通的「指令手册」
提示词是引导智能体工作的「语言指令」,类似给他人布置任务时的详细要求。
优质提示词通常包含明确清晰的几块内容:
「角色定义」*(如 “你是学术论文研究员”)
「任务目标」*(如 “撰写 AI 伦理主题论文”)
「工具调用规则」(如 “补充近五年文献时调用插件”)
「输出规范」*(如 输出文档明确要求包含摘要、引言等模块,并指定 APA 7th 引用格式。)
「少样本示例」(通过一个回答示例,让大模型学习后,它输出的内容更符合样例的模样)。
「输出语气」(如 客服在回答问题时语气注意既专业严谨又体贴用户情绪)。
(以上结构视具体需求,可以自由选择部分使用,打*的建议包含)
提示词参考案例如下:

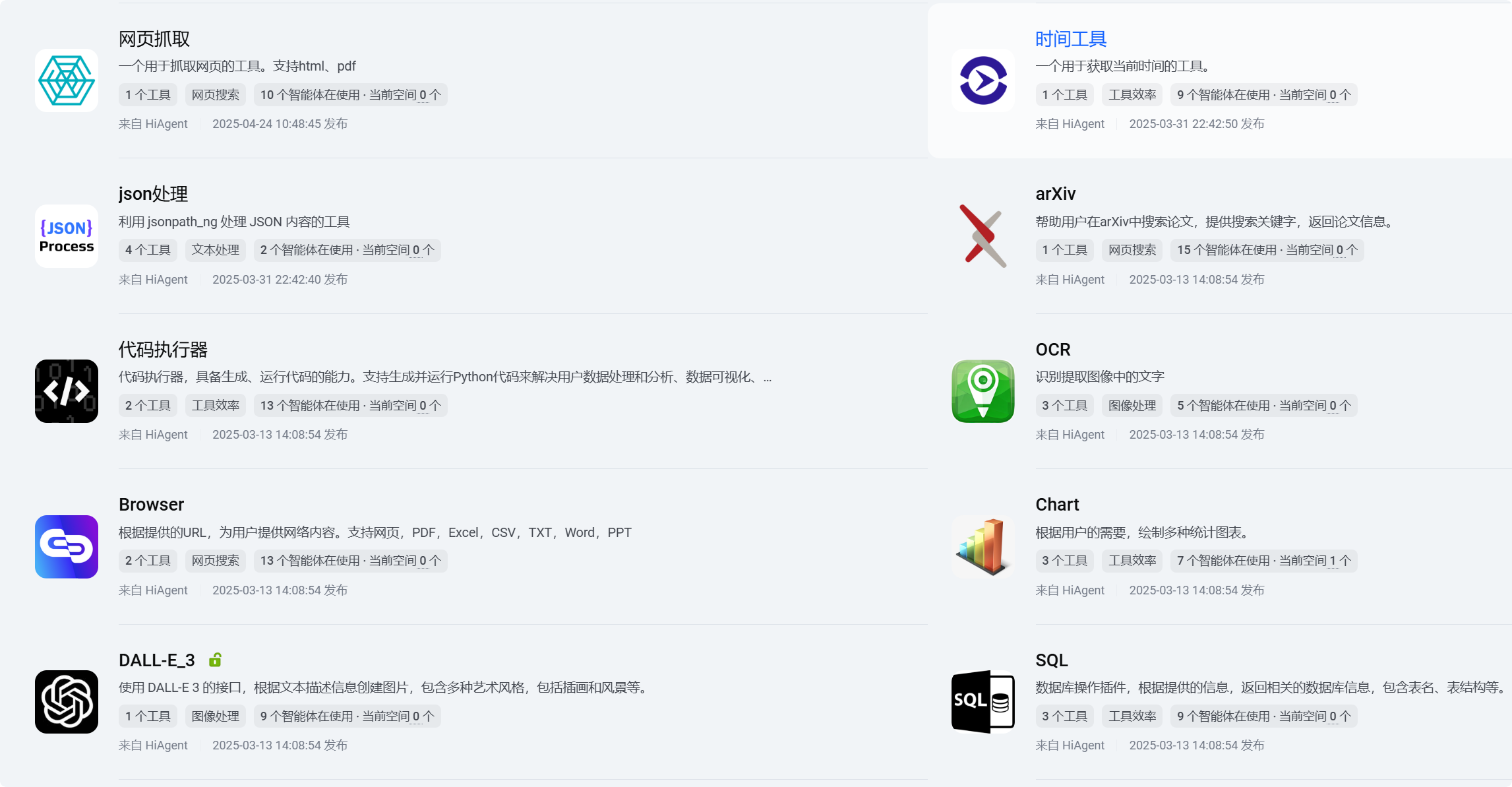
🧰插件:智能体的「万能工具箱」
插件是智能体获取外部能力的「工具接口」,类似手机安装的 APP📱—— 可调用天气 API、文献检索工具、代码解释器等。
应用场景例如:
- 「文献调研助手」通过 arXiv 插件搜索论文;
- 「智能出行助手」调用高德地图导航插件 规划路线
- 「智能图表助手」调用Chart插件绘制图表。
HiAgent平台提供的插件如下图(随着版本不断迭代升级,插件也会越来越丰富,同时支持自定义插件接入):
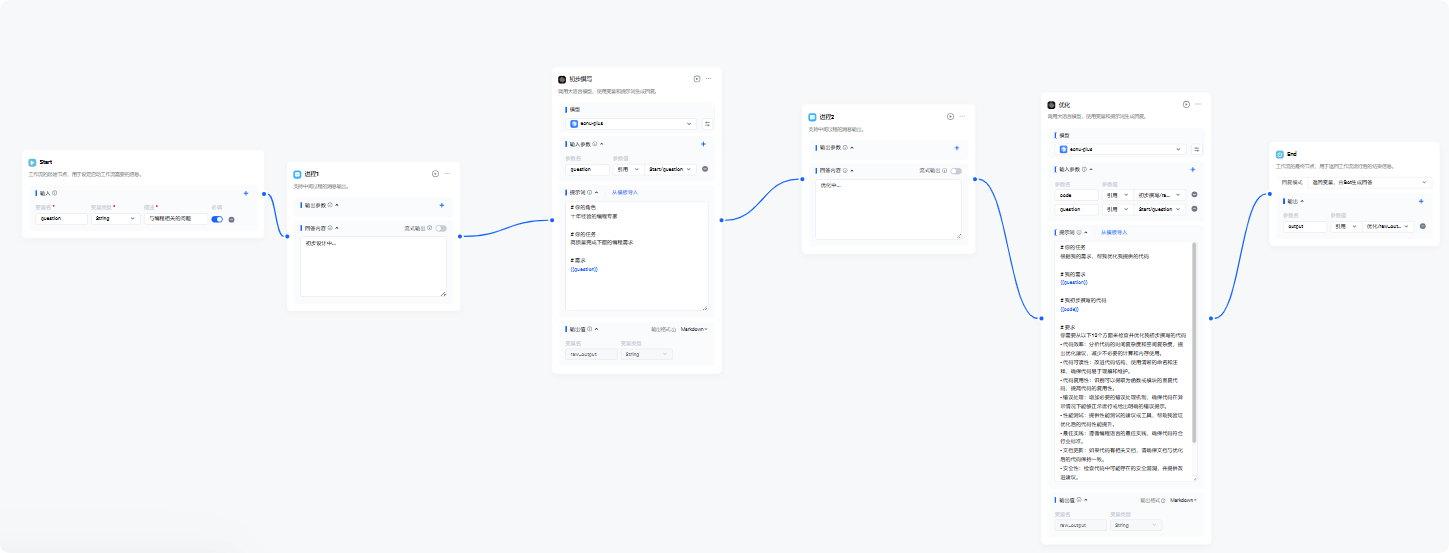
🚂工作流:智能体的「任务流水线」
工作流是将工具与模型按逻辑串联的「自动化流程」,类似工厂的装配线。
例如生成学术论文时,工作流可能按「文献检索插件→大纲生成模型→章节撰写模型→格式优化模型」的顺序执行。
复杂场景可设计并行流程(如多渠道数据同步检索)或反思机制(如一个模型生成代码,另一个模型检查漏洞)。
典型的工作流有:
单一工具流:翻译任务仅需一次模型优化。
多工具串行:AI 搜索引擎先搜索多平台信息,再汇总成调研报告。
多模型反思流:类似 “慢思考” 模式,先规划步骤再逐步执行(如数学题解题流程)。
以下是反思-高质量代码生成的工作流示例:
📁数据库:智能体的「结构化档案柜」
数据库用于存储「结构化数据」(如学生课表、图书借阅记录),特点是格式规范(如 Excel 表格)、查询高效。
智能体通过 SQL 语句精准调取数据(如 “SELECT 教室 FROM 课表 WHERE 时间 = 周一”),例如「校园助手」查询自习教室时,会从数据库筛选空闲时段数据。
与知识库相比,数据库更适合频繁更新和精确查询的场景(如实时考勤记录)。
比较有优势作用的应用场景如:
- 存储规范数据:按表格形式存储课程表、成绩表的场景;
- 精准检索:通过 “字段 = 条件” 快速定位信息(如查询 “张三的选课记录”);
- 数据整合:支持生成个人报告(如学习时长统计、消费分析)。
💡 概念对比
| 概念 | 核心功能 | 典型案例 |
|---|---|---|
| 知识库 | 存储非结构化文本(如校规、文献) | AI辅导员回答奖学金问题 |
| 提示词 | 定义任务规则与输出格式 | 论文撰写提示词 |
| 插件 | 调用外部工具(如天气、文献API) | 文献调研助手检索arXiv |
| 工作流 | 组合工具与模型的自动化流程 | 长论文分段生成流程 |
| 数据库 | 存储结构化数据(如课表、成绩) | 校园助手查询自习教室 |
进阶概念组
📌 以下概念可以先跳过,等以后遇到时,再来研究~
向量化
- 向量化是将文本数据转换为向量空间表示的过程,以便计算机能够处理和分析文本。以下是关于 AI 文本中向量化的详细介绍:
为什么要进行文本向量化
- 文本是一种非结构化数据,计算机难以直接处理和理解。将文本转换为向量后,就可以利用各种机器学习和深度学习算法进行文本分类、情感分析、信息检索、机器翻译等任务。
- 向量空间中的向量可以进行数值计算,如计算向量之间的相似度、距离等,从而衡量文本之间的语义关系。
文本向量化的方法
词袋模型(Bag - of - Words):将文本看作是一个词的集合,忽略词的顺序,只关注每个词在文本中出现的频率。例如,对于文本 “我喜欢苹果,我也喜欢橙子”,可以将其表示为一个向量,向量的每个维度对应一个词,值为该词在文本中出现的次数,如 [我: 2,喜欢: 2,苹果: 1,橙子: 1]。
TF - IDF:在词袋模型的基础上,考虑了词在整个语料库中的重要性。TF(Term Frequency)表示词在文本中出现的频率,IDF(Inverse Document Frequency)表示词在整个语料库中的稀有程度。通过 TF - IDF 计算得到的向量,能够更突出文本中的关键信息。
词向量模型:如 Word2Vec、GloVe 等,通过对大量文本数据进行训练,将每个词映射为一个低维向量。这些向量不仅能够表示词的语义信息,还能捕捉词与词之间的语义关系,如 “国王 - 男人 + 女人 = 王后” 这样的语义类比关系。
基于深度学习的方法:如 BERT、GPT 等预训练语言模型,会在大规模文本数据上进行无监督学习,学习到文本的分布式表示。这些模型能够捕捉文本中的上下文信息,生成更准确、更丰富的文本向量表示。
文本向量化的应用
- 文本分类:将文本向量作为输入,训练分类器,如支持向量机、神经网络等,对文本进行分类,如将新闻文本分为政治、经济、体育等不同类别。
- 情感分析:分析文本所表达的情感倾向,如积极、消极或中性。通过对大量带有情感标注的文本数据进行训练,利用文本向量来预测新文本的情感类别。
- 信息检索:将用户的查询和文档都表示为向量,通过计算向量之间的相似度,快速找到与查询相关的文档。 机器翻译:将源语言和目标语言的文本都向量化,然后利用神经网络模型学习从源语言向量到目标语言向量的映射关系,实现文本的翻译。
RAG
RAG(Retrieval-Augmented Generation),检索增强生成。是一种将检索技术与生成式模型相结合的方法,旨在提高生成式人工智能模型的性能和效果,以下是关于它的详细介绍:
原理
- RAG 模型通常由检索模块和生成模块两部分组成。检索模块负责在大规模的外部知识源(如文档库、知识库、网页等)中进行检索,查找与输入问题或主题相关的信息。生成模块则基于检索到的信息以及模型自身的参数和训练数据,生成自然语言文本作为回答或输出。通过这种方式,RAG 能够利用外部知识来丰富和增强生成的内容,使其更加准确、全面和有针对性。
优点
- 提高准确性:通过检索外部权威知识源,能够获取到最新、最准确的信息,从而使生成的回答更具可靠性,减少模型生成错误或不实信息的可能性。
- 增强知识覆盖:可以涵盖广泛的知识领域,弥补模型自身知识储备的不足,特别是对于一些特定领域或专业知识的问题,能够提供更专业和深入的解答。
- 可解释性增强:检索过程和所使用的外部知识相对透明,有助于用户理解回答的依据和来源,提高了模型的可解释性和可信度。
应用领域
- 问答系统:能够准确回答各种问题,为用户提供高质量的答案。例如在智能客服中,快速准确地回答客户咨询,提高客户满意度。
- 信息检索与推荐:根据用户的查询意图,不仅能返回相关的文档列表,还能生成简洁明了的摘要或推荐内容,帮助用户更快速地获取关键信息。
- 文本生成:在创作文章、报告、故事等文本时,利用 RAG 可以引入相关的背景知识和参考资料,使生成的文本更加丰富和有内涵。
AI Agent
AI Agent 就像是拥有 “超能力” 的智能小助手,能理解周围的情况、自己拿主意做事,帮人们解决各种问题。下面用更通俗的方式介绍它:
像真人一样 “听、想、做”
- “感知”—— 用眼睛耳朵观察环境:它像人用眼睛看、耳朵听一样,接收周围的各种信息。比如智能音箱里的 AI Agent 能 “听” 懂你说的话,扫地机器人里的 AI Agent 能 “看” 到房间里哪里有障碍物、哪里没打扫干净。
- “思考”—— 用大脑做决定:在接收到信息后,它会 “思考” 下一步该怎么办。比如你问智能助手 “周末带孩子去哪儿玩”,它会在自己的 “知识储备库” 里搜索,分析哪里适合亲子活动、天气好不好,然后决定给出哪些建议。
- “行动”—— 动手完成任务:做出决定后,它就开始行动。比如手机里的 AI Agent 能根据你的指令打开某个 APP、发送消息;智能家电里的 AI Agent 能按照设定调节温度、启动工作模式。
不同性格的 “小助手”
- 反应超快的急性子:有一种叫 “反应式 AI Agent”,就像反应敏捷的运动员。比如智能安防系统里的 AI Agent,一旦检测到陌生人闯入,会立刻发出警报,不会考虑太多其他因素,先解决眼前的紧急情况。
- 深思熟虑的慢性子:“慎思式 AI Agent” 更像军师,做事前会把所有情况都想清楚。比如制定旅游计划的 AI Agent,它会综合考虑目的地的景点、交通、住宿、预算等各种信息,反复对比后才给出最佳方案。
- 灵活多变的全能型:“混合式 AI Agent” 结合了前两者的优点,既能快速反应,又能长远规划。就像自动驾驶汽车里的 AI Agent,遇到突然冲出的小动物,会马上刹车避让;同时也会提前规划好路线,根据实时路况调整速度,安全到达目的地。
生活中的得力帮手
- 生活小管家:智能家居里的 AI Agent 可以帮你管理家电。比如你说一句 “我回家了”,它就自动开灯、调节室温、打开电视,让你一进家门就享受舒适生活;智能音箱里的 AI Agent 能陪你聊天、播放音乐、设置闹钟。
- 工作好伙伴:在工作中,AI Agent 可以帮你处理大量数据,比如自动整理表格、分析销售数据;还能帮你写文案,像写邮件、起草报告,提高工作效率。
- 娱乐新玩伴:在游戏里,AI Agent 扮演各种游戏角色,它们会 “思考” 战术、和你斗智斗勇,让游戏更刺激有趣。
MCP
MCP,也就是模型上下文协议,是 2024 年 11 月由 Claude 大模型的公司 Anthropic 推出并开源的一个开放协议。可以将它想象成 AI 世界里的 “通用插座”。就像生活中的 USB - C 接口能让各种设备方便地连接在一起一样,MCP 为 AI 模型连接不同的数据源和工具提供了一种标准化的方式,能帮助 AI 大模型生成更好、更相关的回答。
以前,企业和开发者要把不同的数据接入 AI 系统,都得单独开发对接方案,麻烦又费资源。有了 MCP 后,开发者按照这个标准协议,就能完成 AI 大模型与数据源的集成,不用再为每个数据源、每个 AI 助手维护单独的连接器了。
在 AI Agent 中,MCP 有着重要的应用,主要体现在以下几个方面:
- 让 Agent 能访问更多知识:Agent 可以通过 MCP 连接到各种数据源,比如知识库、文档库等。就像一个学生以前只能看自己家里的书,现在通过 MCP 可以去图书馆、书店等各种地方找书看,知识来源更丰富了,回答问题、解决问题的能力也就更强了。例如,当 Agent 被问到一些专业领域的问题时,它可以通过 MCP 从专业的数据库中获取准确的信息来回答,而不是只依靠自己原本有限的知识储备。
- 使 Agent 的功能更灵活多样:借助 MCP,Agent 能够方便地调用不同的工具和服务。比如说,Agent 要写一篇关于某个城市旅游攻略的文章,它可以通过 MCP 调用地图工具获取景点位置信息,调用天气工具了解当地天气情况,调用交通工具查询交通路线等,然后把这些信息整合起来,写出一篇详细的旅游攻略。这就像一个人原本只会做几件事,现在有了很多工具可以用,能做的事情就大大增加了,而且做得更好。
- 提高 Agent 的安全性和可靠性:MCP 协议内置了访问控制机制和标准化的安全实践。这就好比给 Agent 的知识宝库和工具库都上了一把锁,只有经过授权的 Agent 才能访问和使用这些资源,防止数据被非法访问或篡改,保护用户的数据安全,让 Agent 在处理信息时更加安全可靠。